AI Provenance Citations Guide
Provenance Citations for AI Models: A Guide for Structured Finance
Provenance citations for AI models are no longer an academic exercise; they are a core operational requirement for building trustworthy, auditable AI in high-stakes fields like structured finance. The practice involves generating a verifiable record detailing a model's entire lifecycle—from the exact datasets used for training to every transformation applied. For analysts monitoring remittance data or building risk models, the goal is simple: trace every output back to its source, whether it's an EDGAR filing or a loan-level tape. You can visualize and cite much of this source data using platforms like Dealcharts.
Market Context: Why AI Provenance is Non-Negotiable in Finance
In structured finance, where a single basis point can represent millions in risk, the demand for transparent AI is absolute. Opaque, "black box" models are liabilities. An untraceable model might generate a flawed risk assessment for a Commercial Mortgage-Backed Securities (CMBS) deal or an inaccurate servicer report. Without a clear data trail, diagnosing the error is nearly impossible. This is where provenance citations for AI models become a critical tool for risk management and regulatory compliance.
For analysts and quants, this isn't about compliance theater. It’s a competitive edge that builds institutional trust and ensures reproducibility. The primary challenge is managing model drift, where a model trained on historical remittance data degrades in performance as live market data diverges. Without provenance, identifying this shift is a slow, manual process. With a robust provenance record, an analyst can trace the model's output directly back to the original loan-level tapes and SEC filings used for training, making it easy to compare against current data streams and mitigate critical risks.
- Model Drift: Quickly spot when predictive power weakens due to changes in market conditions.
- Data Poisoning: Detect if corrupted data has entered the training pipeline, skewing outputs.
- Regulatory Scrutiny: Confidently demonstrate that a model is fair, unbiased, and built on traceable data.
A model without provenance is an opinion. A model with clear, verifiable provenance is an auditable fact.
Data & Technical Angle: Sourcing Verifiable Data for AI
To implement provenance citations for AI models, analysts must understand the standards that create a machine-readable, auditable paper trail. The core data originates from public and proprietary sources like EDGAR (for 10-D remittance reports and 424B5 prospectuses) and loan-level data tapes. The technical challenge lies in programmatically accessing, parsing, and linking this unstructured data to specific deals, tranches, and counterparties.
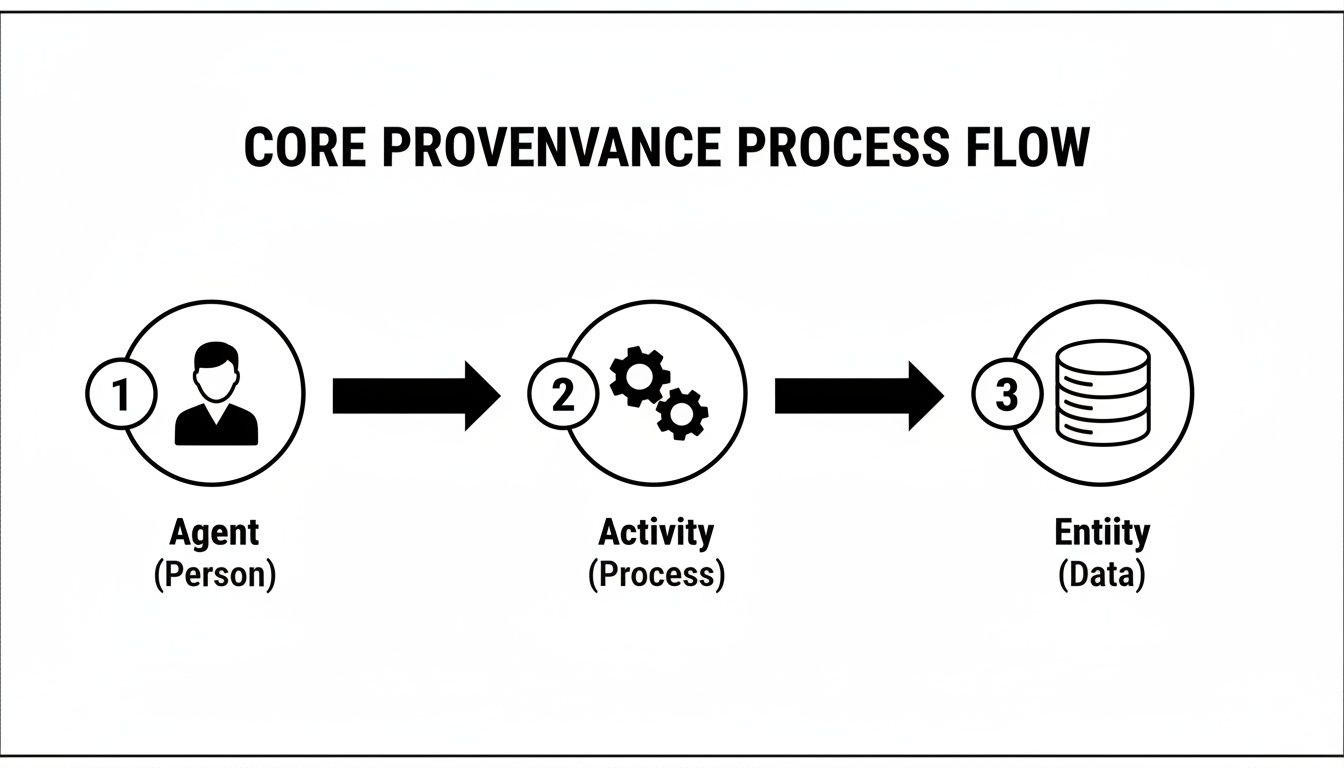
At the core of standards like the W3C PROV Ontology, three concepts map directly to structured finance workflows:
- Entity: The "what"—a 10-D filing, a loan-level dataset for an ABS deal, or the trained risk model itself.
- Activity: The "how"—a data cleaning script run on servicer reports, the training of a neural network, or the generation of a credit risk score.
- Agent: The "who" or "what"—the analyst who ran the model, the Python script that parsed the filing, or an organization.
Connecting these creates a verifiable chain:
. While frameworks like W3C PROV provide the deep auditability, specifications like ODPS (Open Data Product Specification) focus on packaging datasets into citation-ready formats, a model adopted by the Dealcharts dataset. This technical plumbing is crucial for building trustworthy AI.An analyst (Agent) ran a Python script (Activity) to parse a 10-D filing (Entity), creating a structured dataset (another Entity)
According to recent machine learning statistics and what they mean for the industry, while transparency in AI is increasing, only 37% of companies actively track data provenance—a significant gap. Regulatory pressure is mounting; as of 2025, new rules will mandate that AI models must now set out training data provenance, making automated data lineage essential.
Example Workflow: Programmatic Provenance Generation
A practical workflow generates both human-readable summaries (model cards) and machine-readable records (JSON-LD). This systematic process logs every critical step, answering not just what a model predicts, but how it arrived at the conclusion, backed by an immutable data trail. The source (e.g., an SEC filing) is transformed to produce an insight.
For programmatic use, JSON-LD (JSON for Linked Data) is ideal for embedding auditable records directly from analytical scripts. By using a standard vocabulary like the W3C PROV Ontology, a Python script analyzing remittance data from a CMBS deal can automatically generate a verifiable citation.
This snippet creates a basic JSON-LD object describing a data processing activity, demonstrating the data lineage from source to insight.
import jsonfrom datetime import datetime# Define the Agent, Activity, and Entities# This demonstrates the data lineage: source -> transform -> insightactivity_details = {"@context": "https://www.w3.org/ns/prov#","@id": "urn:uuid:activity-12345","@type": "Activity","wasAssociatedWith": {"@id": "urn:analyst:jane.doe","@type": "Agent","name": "Jane Doe"},"used": {"@id": "https://www.sec.gov/Archives/edgar/data/1234567/0001234567-24-000010.txt","@type": "Entity","description": "Source: 10-D filing for CUSIP 987654321"},"generated": {"@id": "urn:dataset:processed-remittance-2024-Q3","@type": "Entity","description": "Insight: Processed remittance data for Q3 2024"},"startedAtTime": datetime.utcnow().isoformat() + "Z"}# Generate the machine-readable JSON-LD outputjson_ld_output = json.dumps(activity_details, indent=2)print(json_ld_output)# This output can be logged for audit purposes.
This code generates a machine-readable record linking the analyst (Agent), the script's execution (Activity), the source 10-D filing (Entity used), and the resulting processed dataset (Entity generated). Baking this logic into analytical scripts builds an automated, trustworthy provenance trail.
Insights and Implications for AI in Finance
Integrating this structured context improves financial modeling, risk monitoring, and LLM reasoning significantly. Static citations are a snapshot; weaving provenance directly into automated workflows creates an unbroken chain of trust. When an AI model processes a deal, it can programmatically trace a CUSIP back to its source 424B5 prospectus, maintaining that link through every analytical step.
This enables "model-in-context" reasoning. For a Large Language Model (LLM), it means it can do more than generate an answer; it can cite the specific deal documents, servicer reports, or remittance files that support its conclusion. This is the core theme of CMD+RVL's context engine philosophy: transforming opaque, black-box assertions into verifiable, data-backed insights. When an LLM summary states, "loan concentration in the retail sector has increased by 5%," it can instantly surface the exact 10-D filings used.
An immutable provenance trail also streamlines verification and compliance. This systematic approach allows teams to find errors faster, simplify regulatory audits, and automate validation checks. Every script, transformation, and model training run must generate a provenance record, building explainable pipelines that hold up to scrutiny.
How Dealcharts Helps
Building and maintaining provenance pipelines from scratch is resource-intensive data plumbing. Dealcharts provides a verifiable foundation by offering a pre-linked, open context graph of structured finance data. It connects SEC filings, deals, issuance shelves, and counterparties, creating a ready-made source of truth for your models.
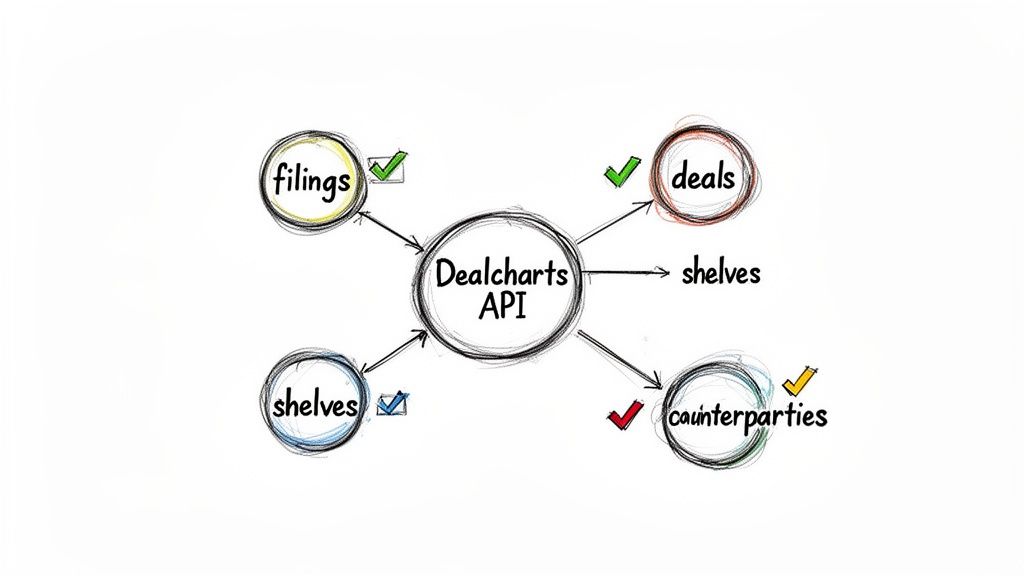
Dealcharts connects these datasets—filings, deals, shelves, tranches, and counterparties—so analysts can publish and share verified charts without rebuilding data pipelines. By building on Open Data Product Specification (ODPS) standards, Dealcharts ensures every data point is attributable by design. This provides the bedrock for generating robust provenance citations for AI models without the manual overhead, allowing your models to consume clean, verifiable inputs from day one.
Conclusion
In AI-driven finance, context and explainability are paramount. Provenance citations for AI models are how we move structured finance from opaque analytics to transparent, verifiable insights. This isn't just about compliance; it's about building more robust, reliable, and defensible financial models. The endgame is an ecosystem where every analytical claim is backed by an immutable chain of evidence—the foundation of the broader CMD+RVL framework for reproducible, explainable finance analytics.
Article created using Outrank