Student Loan Backed Securities
A Data-Driven Guide to Student Loan Backed Securities
For structured-finance analysts, data engineers, and quants, student loan backed securities (SLBS) are not just abstract financial instruments; they are complex data puzzles. At their core, these securities are pools of thousands of student loans, bundled and sold to investors. The real challenge lies in transforming the messy, high-volume cash flows from individual borrowers into a predictable, tradable asset. This requires a granular understanding of the underlying data, from origination tapes to remittance reports, and the ability to programmatically trace its lineage from source to insight. This guide focuses on the technical workflow for analyzing SLBS, moving beyond surface-level explainers to cover data sourcing, programmatic analysis, and verifiable modeling. We'll explore how to connect raw data from SEC filings to actionable risk metrics, a process streamlined by platforms like Dealcharts that visualize and cite this complex data lineage.
Market Context: Trends and Challenges in Student Loan ABS
Student loan backed securities are a significant component of the asset-backed securities (ABS) market, providing essential liquidity to the student lending ecosystem. Unlike a simple corporate bond, an SLBS's performance is tied to the collective behavior of thousands of individual borrowers, making its analysis inherently data-intensive. The market is broadly divided into two categories: securities backed by government-guaranteed Federal Family Education Loan Program (FFELP) loans and those backed by private student loans. For FFELP-backed deals, the primary risk is timing and servicer efficiency, as the U.S. government backstops credit losses. In contrast, private SLBS deals carry direct credit risk, making granular analysis of borrower behavior and collateral performance critical.
Currently, the market faces unique challenges. The post-pandemic resumption of federal loan payments has introduced significant uncertainty into performance forecasts. Analysts are closely monitoring delinquency and default rates in monthly remittance reports, as these metrics directly impact the cash flows available to bondholders. These trends underscore the necessity of a data-first approach, grounded in verifiable sources. You can see how SLBS stacks up against other sectors by checking out the 2023 ABS issuance trends. In this environment, an analyst's edge comes from the ability to trace data from its source and build models that reflect real-world collateral behavior.
Data Sources and Programmatic Access for SLBS Analysis
Verifiable SLBS analysis depends on accessing and parsing data from primary sources. The most critical documents are filed with the SEC and available through the EDGAR database. Key data sources include:
- Form 424B5 (Prospectus): This document details the initial deal structure, including the cash flow waterfall logic, credit enhancement levels (like overcollateralization and excess spread), and performance triggers. It is the rulebook for the security.
- Form 10-D (Periodic Distribution Report): Filed monthly or quarterly, this report contains the servicer's remittance report as an exhibit. This is the ground truth for collateral performance, containing data on delinquencies, defaults, prepayments, and collections.
- Loan-Level Tapes: For many deals, issuers provide anonymized loan-by-loan data, offering the most granular view of the underlying collateral pool.
Accessing this data programmatically is essential for any scalable surveillance workflow. The SEC's EDGAR API provides a direct interface to fetch these filings. An analyst or data engineer can build a pipeline that maps a deal's CUSIP to its Central Index Key (CIK) to automate the retrieval of
filings as they are published. The primary challenge is parsing the exhibits, as formats are not standardized across issuers, requiring custom logic for each servicer. Platforms like Dealcharts solve this problem by ingesting, parsing, and standardizing data from these filings, linking it to deals, tranches, and counterparties.10-D
Example Workflow: Programmatic Retrieval of 10-D Filings
A practical surveillance workflow begins with automating data retrieval. This Python snippet demonstrates how to use the EDGAR API to find the latest 10-D filing for a specific SLBS trust. This is the first step in establishing an explainable data pipeline: source → transform → insight. The code fetches the filing metadata, allowing an analyst to then target the specific remittance report exhibit for parsing.
import requestsimport json# Example: Programmatically find the latest 10-D for an SLBS trust# This script establishes the first link in the data lineage chain: CUSIP -> CIK -> Filing.# Define the CIK for a specific SLBS trust and headers for the request# CIK for Navient Student Loan Trust 2017-3 as an exampleCIK = "0001705915"headers = {'User-Agent': "Analyst Name analyst@firm.com"}# Construct the URL to fetch company submissions from EDGAR# This is the primary source of the data.url = f"https://data.sec.gov/submissions/CIK{CIK}.json"# Make the API requestresponse = requests.get(url, headers=headers)data = response.json()# Filter for the most recent 10-D filing from the returned JSONrecent_filings = data['filings']['recent']ten_d_accession_number = Noneprimary_document = Nonefor i in range(len(recent_filings['form'])):if recent_filings['form'][i] == '10-D':# Accession number is the unique identifier for the filing.ten_d_accession_number = recent_filings['accessionNumber'][i].replace('-', '')primary_document = recent_filings['primaryDocument'][i]break# The output is a direct link to the source document, ready for parsing.if ten_d_accession_number:filing_url = f"https://www.sec.gov/Archives/edgar/data/{CIK}/{ten_d_accession_number}/{primary_document}"print(f"Found latest 10-D: {primary_document}")print(f"Verifiable Source URL: {filing_url}")else:print("No recent 10-D filing found.")
This workflow ensures that any analysis is grounded in verifiable, primary-source data. The subsequent step—parsing the actual remittance report—is where the complexity lies due to non-standard formats. However, establishing this programmatic link is the foundation of any robust, reproducible analysis.
Implications for Modeling and Risk Monitoring
A structured, programmatic approach to SLBS data fundamentally improves modeling, risk monitoring, and even the reasoning capabilities of Large Language Models (LLMs). When a model is built on a foundation of verifiable data lineage—where every input can be traced back to a specific filing and table—it becomes an explainable pipeline. This is the core theme of "model-in-context." An analyst can stress-test a deal's cash flow waterfall against various economic scenarios (e.g., rising unemployment) and pinpoint exactly how performance triggers would be breached and cash flows redirected.
This context-rich data also enhances AI applications. An LLM armed with structured, interconnected data from prospectuses and remittance reports can answer complex queries like, "Which tranches in the BMARK 2024-V9 deal are most exposed to a 10% increase in 90+ day delinquencies?" This moves beyond simple data retrieval to genuine financial reasoning, enabled by a context engine that understands the relationships between deals, collateral, and performance metrics.
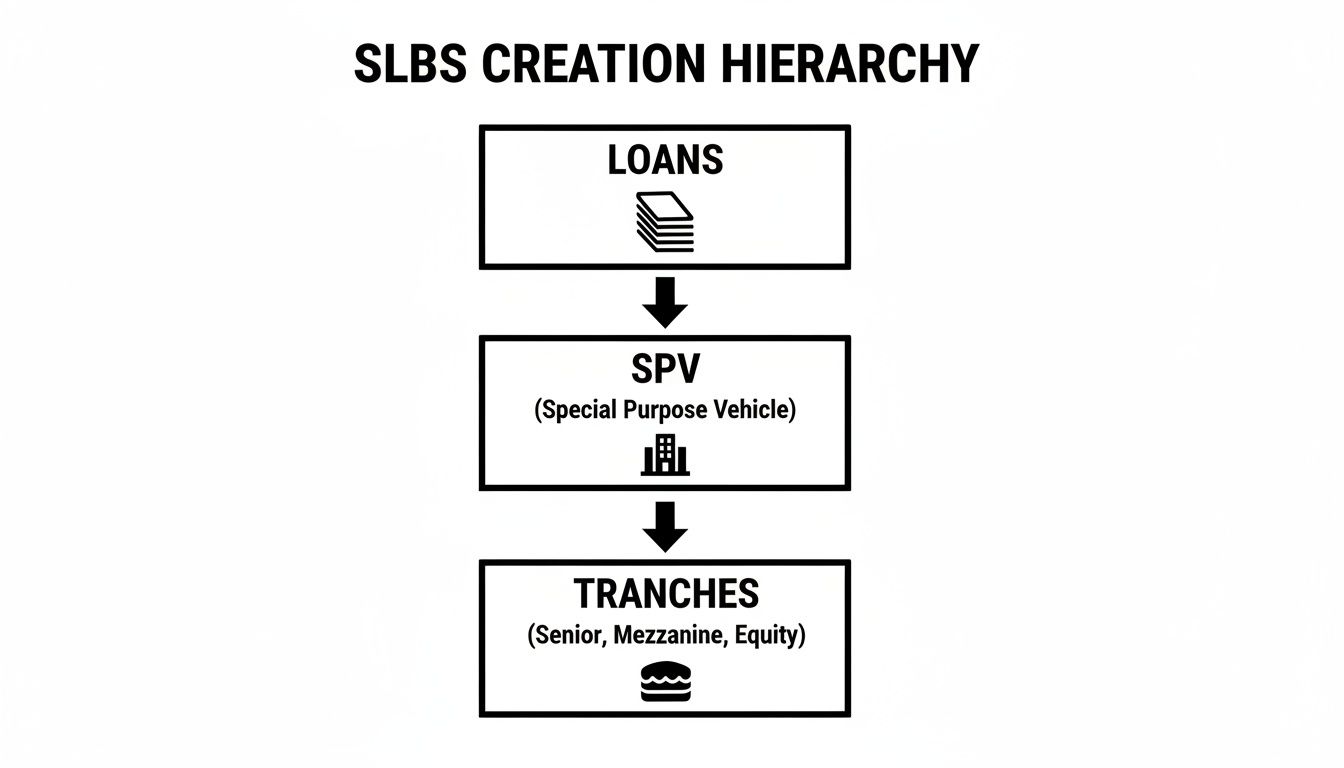
How Dealcharts Accelerates SLBS Analysis
The primary bottleneck in advanced SLBS analysis is not a lack of data, but the engineering effort required to make it usable. Analysts spend an inordinate amount of time sourcing, parsing, cleaning, and linking disparate datasets from filings, deals, shelves, and tranches. Dealcharts connects these datasets automatically, so analysts can publish and share verified charts without rebuilding data pipelines. By providing structured, linkable data with clear lineage, it allows quants and analysts to focus on modeling and insight generation rather than data plumbing.
Conclusion
Analyzing student loan backed securities effectively requires a shift from manual, opaque processes to programmatic, explainable workflows. By grounding analysis in verifiable data lineage—tracing every number from its source in public filings—analysts can build more robust models and gain deeper insights into risk and performance. This data-centric mindset is the foundation of reproducible, explainable finance analytics, enabling professionals to move beyond simply reporting numbers to truly understanding the mechanics that drive them.