Human-in-the-Loop Data Quality
A Guide to Human-in-the-Loop Data Quality in Structured Finance
In structured finance, speed is critical, but accuracy is paramount. Algorithms excel at processing massive datasets, but they often falter when faced with the non-standardized data common in EDGAR filings or loan-level tapes. This is where Human-in-the-Loop (HITL) data quality becomes essential, acting as the crucial bridge between machine efficiency and expert human judgment. For analysts and quants monitoring remittance data or building risk models, an auditable HITL process ensures that automated outputs are not just fast, but verifiable. This guide breaks down why HITL is a non-negotiable component of modern data infrastructure in credit markets.
Market Context: The Need for Verifiable Data in CMBS/ABS
Getting clean, trustworthy data in structured credit markets like CMBS and ABS is a persistent challenge. While automated pipelines promise efficiency, they introduce subtle risks that can silently corrupt financial models. The core problem originates with the source documents—a 424B5 prospectus or a 10-D remittance report is filled with nuanced legal language and complex tables that can easily trip up an automated parser or a large language model.
This leads to "silent failures"—errors where an automated system produces data that looks correct but is fundamentally wrong. For instance, an NLP model might misinterpret a servicer comment, confusing a loan in a "grace period" with one in "foreclosure." These aren't minor rounding errors; they are foundational mistakes that can invalidate a risk assessment. As issuers continually evolve their reporting formats (data drift), models trained on historical filings can degrade in accuracy without triggering explicit warnings. For regulated institutions, this lack of explainability is a significant compliance and financial risk.
The Data & Technical Angle for Human-in-the-Loop Data Quality
A robust HITL framework integrates automated processing with expert oversight to create a transparent, auditable data pipeline. It is not about manual review of every data point; it's about targeted intervention where automation is most likely to fail. The process transforms opaque, automated outputs into a verifiable source of institutional knowledge.
This system is built on four core components:
- Automated Ingestion: Scripts pull source documents from repositories like the SEC's EDGAR database as they are published.
- AI-Powered Extraction: NLP or computer vision models parse unstructured documents (PDFs, HTML) to extract key fields like delinquency statuses, loan modifications, or servicer comments into a structured format like JSON.
- Human Review Interface: An efficient UI presents the AI's extracted data side-by-side with the highlighted source text, allowing an analyst to verify, correct, or generate data points with full context.
- Continuous Feedback Loop: Every human correction is logged and used as a new training example, systematically improving the extraction model's accuracy over time.
This turns the data pipeline from a one-way street into a self-improving ecosystem. A surprising 76% of enterprises now use human-in-the-loop processes to mitigate AI hallucinations and ensure data quality, viewing it as critical for reliable deployment. You can read the full research about these AI statistics.
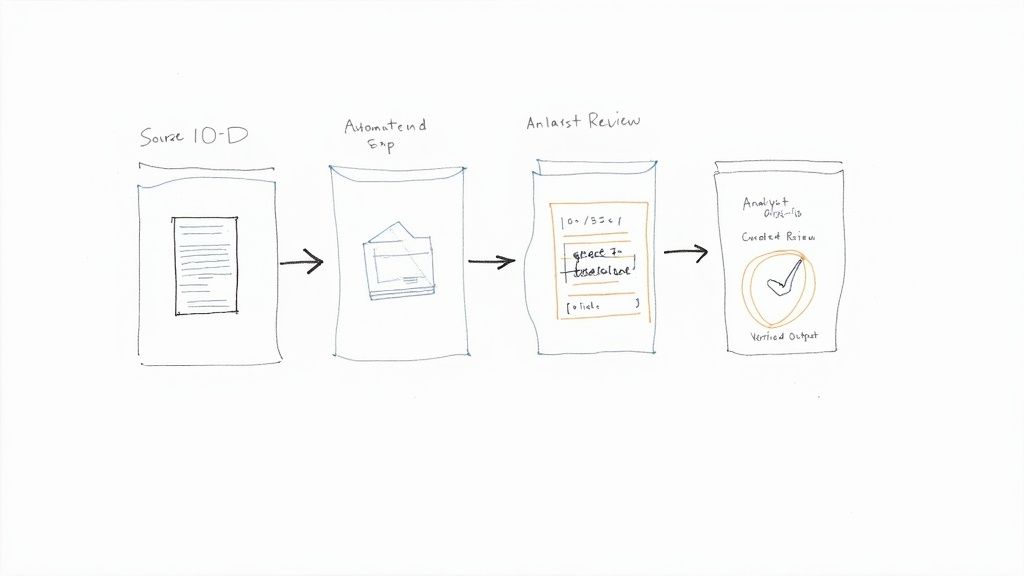
Example Workflow: Verifying a CMBS 10-D Remittance Report
Let's apply this framework to a practical task: processing a monthly CMBS 10-D remittance report from EDGAR. These documents are dense, critical for surveillance, and filled with subtleties that automated systems can miss.
The goal is to establish a clear data lineage: Source (EDGAR) → Transform (NLP) → Verification (Human Analyst) → Insight (Verified Metric).
Here is a Python snippet illustrating the first step—programmatically fetching a 10-D filing using its CIK (Central Index Key) and Accession Number.
import requestsimport os# Define filing details for a specific 10-D report# Example: BMARK 2024-V7, filed on 2024-11-15CIK = "0001999863" # Central Index Key for the issuerACCESSION_NUMBER = "0001539497-24-001882" # Unique identifier for the filing# Construct the URL to the primary filing document on the EDGAR archives# The URL format removes dashes from the accession numberACCESSION_NUMBER_NO_DASH = ACCESSION_NUMBER.replace("-", "")FILENAME = "d10d.htm" # Common name for the 10-D report filefiling_url = f"https://www.sec.gov/Archives/edgar/data/{CIK}/{ACCESSION_NUMBER_NO_DASH}/{FILENAME}"headers = {"User-Agent": "Your Name Your-Company your.email@example.com"}# Fetch the filing contenttry:response = requests.get(filing_url, headers=headers)response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)# Save the filing locally for parsingwith open(f"{ACCESSION_NUMBER}.html", "w", encoding="utf-8") as f:f.write(response.text)print(f"Successfully downloaded filing: {ACCESSION_NUMBER}")except requests.exceptions.RequestException as e:print(f"Error fetching filing: {e}")
Once the HTML is fetched, an NLP model extracts key data points. The crucial step is human verification. An analyst reviews the extracted data and spots a subtle error. The model tagged a loan as "Foreclosure," but the servicer comment reads: "Borrower is in a grace period while finalizing workout." The analyst corrects the status to "Grace Period." This correction is not just a data fix; it becomes a new training example logged with the analyst's ID and a timestamp, improving the model for the next cycle. This process creates an unbroken, auditable chain of evidence.
Insights and Implications for Financial Modeling
Implementing a Human-in-the-Loop (HITL) process builds a proprietary, high-fidelity dataset that becomes a lasting competitive advantage. When data is structured and verified, downstream applications—from risk models to LLM-based reasoning engines—become more robust and reliable. This methodology creates a "model-in-context" framework, where every input is auditable back to its source document.
This has several key implications:
- Explainable Pipelines: When a model produces an unexpected result, analysts can trace the data lineage from the output back through the verification step to the original filing. This eliminates the "black box" problem common in purely automated systems.
- Improved Risk Modeling: Models trained on human-verified data are more resilient to the ambiguous language and formatting inconsistencies found in financial disclosures, leading to more accurate credit surveillance and risk assessment.
- Enhanced LLM Reasoning: Feeding a Large Language Model high-fidelity, structured data dramatically improves its ability to reason about complex financial scenarios. It can ground its outputs in verified facts from a trusted knowledge base, rather than generating plausible but incorrect information.
This verified dataset acts as a flywheel. Better data leads to better models, which produce more reliable insights. An analyst investigating the performance of CMBS vintage 2019 data available on Dealcharts can do so with confidence, knowing the underlying numbers have been validated against source filings.
How Dealcharts Helps
Building a custom human-in-the-loop pipeline from scratch is a significant engineering effort. Dealcharts connects these datasets — filings, deals, shelves, tranches, and counterparties — so analysts can publish and share verified charts without rebuilding data pipelines. We operationalize human-in-the-loop data quality, giving your team direct access to pre-verified, structured data. For example, instead of manually parsing filings for a new issue like the BMARK 2024-V7 CMBS deal, your team can access verified data immediately, accelerating analysis and improving model accuracy.
Conclusion
Human-in-the-loop data quality is not a bottleneck but a strategic imperative for any firm relying on automated analysis in structured finance. It builds an auditable, self-improving data infrastructure that produces verifiable, high-fidelity outputs. This fusion of machine scale and human expertise creates a durable competitive advantage grounded in data context and explainability. It is a foundational component of the CMD+RVL framework, which enables reproducible and transparent financial analytics.
Article created using Outrank