RAG for SEC Filings with Provenance
Building RAG for SEC Filings with Provenance: A Guide for Analysts
Retrieval-Augmented Generation (RAG) for SEC filings is more than a chatbot—it's an engine for verifiable financial intelligence. The objective is to build a system that can answer complex questions about remittance data, risk factors, or deal covenants while explicitly citing the exact source for every data point. This requires combining a powerful language model with a high-fidelity retrieval system that pulls directly from filings, ensuring every output is traceable and robust enough for high-stakes analysis. For analysts monitoring CMBS deals or parsing prospectuses, this moves AI from a novelty to a mission-critical tool for auditable research.
Market Context: The Analyst's Dilemma
Financial analysts, data engineers, and quants face a constant paradox: drowning in documents but starving for intelligence. The relentless flow of SEC filings—from dense 10-Ks to convoluted 424B5 prospectuses—creates a significant bottleneck. The challenge isn't just volume; it's the crisis of confidence in manually extracted data.
Manual review is inefficient and prone to error. Traditional keyword searches are blunt instruments, often missing critical context buried in footnotes or complex tables. This inefficiency slows down risk monitoring, model validation, and deal surveillance. For any serious financial professional, a number without a source is worthless. Decisions depend on auditable data lineage.
This is where RAG becomes essential, but only if it meets one non-negotiable principle: provenance. An AI-generated answer without an unbreakable link back to its source is merely a well-educated guess. Building a RAG system for SEC filings with provenance isn't just a technical upgrade; it’s a foundational requirement for creating AI tools that are trustworthy in a regulated environment. The goal is to transform opaque documents into a network of verifiable facts where every data point can answer the question: "Show me exactly where this came from."
- Trust and Auditability: Every insight is backed by a direct link to the source document, page, and section, satisfying compliance and streamlining internal reviews.
- Improved Accuracy: Grounding LLM answers in specific, retrieved text dramatically reduces the risk of "hallucinations."
- Accelerated Research: Analysts can ask complex questions and receive cited answers in seconds, freeing them to focus on strategy instead of data extraction.
For instance, a CMBS analyst examining property-level debt service coverage ratios in a specific vintage, like 2023 CMBS deals, needs precise figures from remittance reports. A provenance-aware RAG system can retrieve and cite those numbers, providing a rock-solid, auditable basis for their analysis.
The Data & Technical Angle: Sourcing Verifiable Data
Any trustworthy AI is only as good as its data foundation. For a RAG system handling SEC filings, this means starting with a robust, metadata-aware ingestion pipeline. The goal isn’t to just rip text out of documents; it's to create a structured, verifiable dataset from raw, often messy public filings.
This process starts with sourcing documents directly from reliable endpoints like the SEC's EDGAR API. However, fetching the files is the easy part. The real work is parsing the mix of formats—HTML, XBRL, PDF, and plain text—without losing critical context.
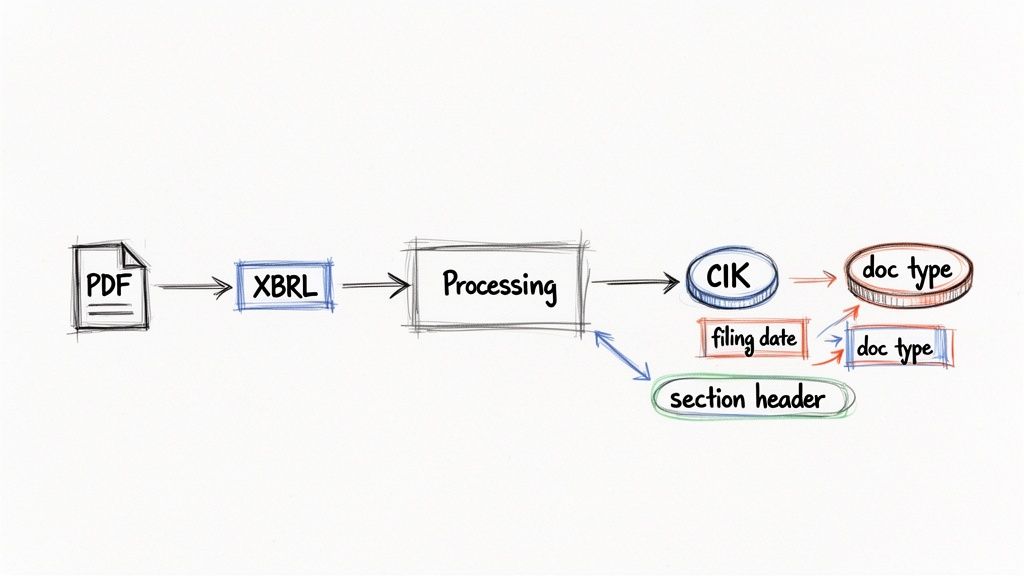
A common mistake is converting everything to raw text, which strips away structural and semantic information. A better approach is to normalize formats into a consistent schema, like structured JSON, while preserving the original document hierarchy.
The core principle is capturing provenance metadata at the point of ingestion. This is non-negotiable. Every piece of extracted data must be tagged with its origin story before it sees a chunker or an embedding model.
This foundational metadata layer makes true data lineage possible. At a minimum, every extracted segment of a filing should be enriched with these attributes:
- CIK (Central Index Key): The unique identifier for the company.
- Accession Number: The unique ID for that specific filing.
- Filing Date: The date the document was officially filed.
- Document Type: The form type, like
,10-K
, or10-D
.424B5 - Source Filename: The specific file within the submission (e.g.,
).ex-99.1.htm - Structural Context: Page number, section header (
), or table ID.Item 1A. Risk Factors
Without this metadata, you have a disconnected soup of text. With it, you build a knowledge graph where every node understands its place in the universe of financial reporting.
Workflow Example: Building a Provenance-Aware Pipeline
Here is a simplified Python example demonstrating how to fetch a filing and parse it while attaching critical metadata from the start. This snippet uses the
library to retrieve a filing andsec-api
to parse its HTML, laying the groundwork for a true provenance-aware pipeline.BeautifulSoup
import requestsfrom bs4 import BeautifulSoup# --- Configuration ---# Example: Apple Inc. (CIK: 320193) 2023 10-KCIK = "320193"ACCESSION_NUMBER = "0000320193-23-000106"PRIMARY_DOCUMENT = "aapl-20230930.htm"API_KEY = "YOUR_SEC_API_KEY" # Replace with your key# --- 1. Fetch the Filing ---# Construct the URL for the raw filing from SEC EDGAR.url = f"https://www.sec.gov/Archives/edgar/data/{CIK}/{ACCESSION_NUMBER.replace('-', '')}/{PRIMARY_DOCUMENT}"headers = {'User-Agent': 'YourAppName/1.0 your-email@domain.com'}response = requests.get(url, headers=headers)response.raise_for_status() # Ensure the request was successfulhtml_content = response.text# --- 2. Parse and Extract with Provenance ---soup = BeautifulSoup(html_content, 'lxml')# This is a simplified extraction. A production system would# identify sections, tables, and paragraphs more robustly.data_with_provenance = []paragraphs = soup.find_all('p')for i, p_tag in enumerate(paragraphs):text = p_tag.get_text(strip=True)if len(text) > 50: # Filter out short/empty paragraphs# Create a dictionary capturing the content and its originrecord = {"content": text,"metadata": {"cik": CIK,"accession_number": ACCESSION_NUMBER,"document_name": PRIMARY_DOCUMENT,"filing_date": "2023-10-27", # Hardcoded for example"element_type": "paragraph","element_index": i}}data_with_provenance.append(record)# --- 3. Output ---# Display the number of extracted records and an exampleprint(f"Extracted {len(data_with_provenance)} records with provenance.")if data_with_provenance:print("\n--- Example Record ---")print(data_with_provenance[0])
This snippet shows the first step: source → transform. A production-grade system would expand this logic to handle tables and identify section headers, enriching the metadata further. Embedding provenance from the start ensures that every subsequent stage—chunking, embedding, and retrieval—operates on a foundation of verifiable data.
This disciplined approach is what separates a generic document Q&A tool from a professional-grade financial analysis engine. It ensures the lineage is preserved, transforming raw filings into a searchable, reliable knowledge base.
Insights and Implications: Context-Aware Reasoning
Structuring SEC filing data with provenance does more than improve search; it enables higher-order reasoning for risk monitoring and modeling. When an LLM receives not just text but also its context—CIK, filing type, section header—it can generate far more nuanced and accurate insights. This is the core idea behind a "model-in-context" framework.
A generic RAG pipeline treats all text as equal. In contrast, a provenance-aware system understands that a number from a
filing's audited financial statement carries more weight than a projection from a10-K
prospectus. This structured context helps the LLM distinguish between hard facts, risk disclosures, and forward-looking statements.424B5
Consider an analyst asking, "What were the total auto loan originations for CIK 12345 in their Q4 2023 10-K, and what were the associated credit enhancement levels?"
- Retrieval: A hybrid search queries the vector store for chunks tagged with
,CIK: 12345
, and a Q4 2023document_type: 10-K
. It retrieves relevant paragraphs from "Management's Discussion and Analysis" and structured data from parsed tables detailing credit enhancements.filing_date - Augmentation: Retrieved chunks, along with their provenance metadata (e.g.,
), are bundled into the LLM prompt.{"source": "aapl-20231027.htm", "section": "Item 7"} - Generation: The LLM synthesizes the information and generates a precise, sourced answer: "In their Q4 2023 10-K, CIK 12345 reported total auto loan originations of $2.5 billion [Source: 10-K, Item 7, pg. 45]. The deal was supported by a 5% overcollateralization and a 1.5% cash reserve account [Source: 10-K, Exhibit 99.1, Table 3.2]."
This level of detail, with verifiable citations, elevates a generic chat tool into a dependable financial analysis engine. The provenance isn't just metadata; it's the foundation of trust.
How Dealcharts Helps
Building a custom, provenance-aware RAG pipeline is a massive data engineering lift. Dealcharts short-circuits this entire process. We provide pre-connected datasets with provenance baked in from the start, linking filings, deals, shelves, and counterparties into a single, navigable context graph. This allows analysts to publish and share verified charts without rebuilding data pipelines. For instance, you can trace data from a specific issuance, like the J.P. Morgan CMBS shelf, directly back to its source filings.
Conclusion
Building a RAG for SEC filings with provenance is not just about finding answers; it's about building trust through data lineage and explainability. By meticulously sourcing, parsing, and tagging data with its origin, we create systems that provide verifiable, context-rich insights. This approach transforms AI from a black box into a transparent tool that meets the rigorous demands of financial analysis. This is the foundation of the CMD+RVL framework: enabling reproducible, explainable analytics for professionals.
Article created using Outrank