CMBS Loans Guide
A Data-Driven Guide to CMBS Loans and Securitization
Commercial Mortgage-Backed Security (CMBS) loans are a cornerstone of structured finance, yet their underlying data lineage is often opaque. For analysts, data engineers, and quants, understanding what are CMBS loans is less about the surface-level definition and more about tracing the data from an individual property's cash flow to the performance of a tradable bond. This process, known as securitization, pools individual commercial mortgages and issues bonds against their collective cash flows. The entire ecosystem—from risk modeling to investor reporting—depends on programmatic access to verifiable, source-level data from filings. Platforms like Dealcharts are built to visualize and cite this critical data lineage, connecting raw remittance files to actionable market insights.
CMBS Market Context and Structure
CMBS loans are not just financial instruments; they are a critical source of capital for the commercial real estate market. By pooling loans on diverse assets—from office buildings and retail centers to industrial warehouses—securitization creates liquidity for lenders and investment opportunities for capital markets participants. The structure is designed to distribute risk. A pool of loans is transferred to a trust, which then issues a series of bonds, or tranches, each with a different risk-return profile determined by its position in the payment "waterfall."
A significant recent trend is the market's shift from traditional conduit deals, which prioritize diversification across hundreds of smaller loans, to Single-Asset, Single-Borrower (SASB) transactions. SASB deals are backed by a single, large loan on a trophy asset or a portfolio owned by one sponsor. This shift concentrates risk, making loan-level due diligence and ongoing surveillance even more critical. As of Q3 2023, SASB issuance accounted for nearly 73% of the private-label CMBS market, underscoring the need for analytical tools that can handle both diversified and concentrated risk profiles.
The Data Lineage: What are CMBS Loans from a Technical Perspective?
The source of truth for any CMBS transaction resides in public filings submitted to the U.S. Securities and Exchange Commission's EDGAR database. For analysts and developers, programmatic access to this data is the first step in any credible workflow.
Key source documents include:
- Form 424B5 (Prospectus): Filed at issuance, this document contains the initial loan-level data tape as an exhibit. It provides a static snapshot of every loan in the pool, including property type, underwriting metrics like Net Operating Income (NOI), Loan-to-Value (LTV), and Debt Service Coverage Ratio (DSCR).
- Form 10-D (Servicer Reports): Filed periodically (usually monthly), these reports provide ongoing remittance data. They contain dynamic, loan-level performance updates, such as current principal balance, payment status, delinquency flags, and any transfers to special servicing.
Accessing this data involves identifying the deal's CIK (Central Index Key) and parsing these filings, which are often in unstructured text or HTML formats. This raw data is the foundation for building any surveillance model, risk engine, or market analysis. The Dealcharts platform automates the extraction and structuring of this data from issuers like JP Morgan Chase Commercial Mortgage Securities Corp. to provide clean, verifiable datasets.
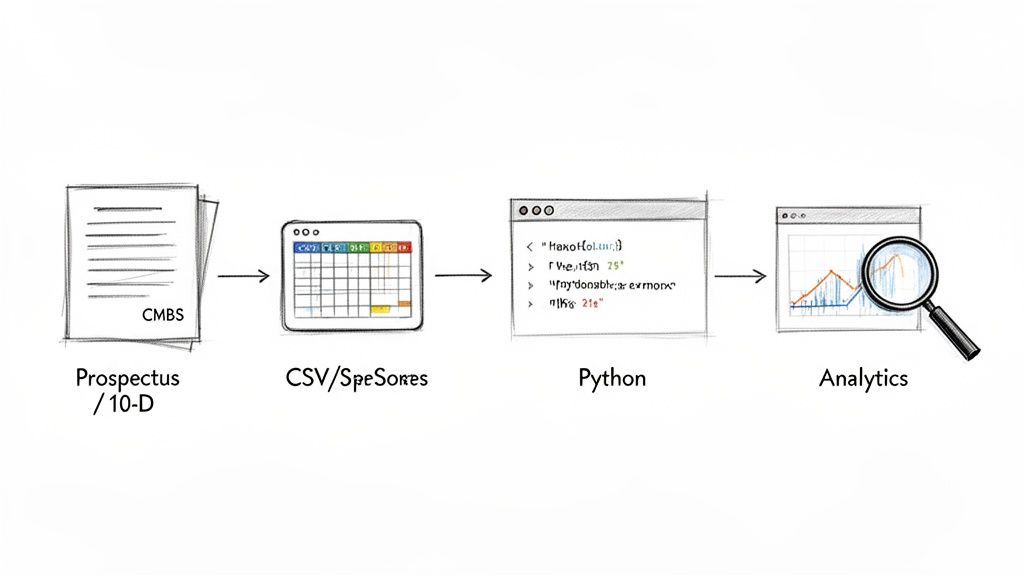
Example Workflow: Programmatic CMBS Data Extraction
A common task for a quantitative analyst is to extract and analyze loan-level data from a prospectus. This requires a script that can fetch the filing, locate the data tape exhibit, and parse it into a structured format like a Pandas DataFrame.
The data lineage is explicit: Source (EDGAR 424B5 filing) → Transform (Python parsing script) → Insight (DataFrame analysis).
Here is a simplified Python snippet demonstrating this concept:
import requestsimport pandas as pdfrom bs4 import BeautifulSoup# Example: Fetch a hypothetical filing from the SEC EDGAR archive# Note: Real URLs are more complex and require CIK/accession number lookup.filing_url = 'https://www.sec.gov/Archives/edgar/data/...' # URL to the 424B5 filingresponse = requests.get(filing_url)# Use BeautifulSoup to parse the HTML and find the loan tape tablesoup = BeautifulSoup(response.text, 'html.parser')# The table ID or class will vary by issuer and filing formatloan_tape_table = soup.find('table', {'id': 'loanTapeExhibit'})# Convert the HTML table to a Pandas DataFrameif loan_tape_table:df = pd.read_html(str(loan_tape_table))[0]# Clean and standardize columns (e.g., 'DSCR', 'LTV', 'NOI')df.columns = ['LoanID', 'PropertyType', 'City', 'State', 'OriginalBalance', 'LTV', 'DSCR']print("Successfully parsed loan tape:")print(df.head())else:print("Could not find the loan tape exhibit in the filing.")# Insight: Calculate weighted average DSCR for the pool# Ensure numeric conversion and handle potential errorsdf['OriginalBalance'] = pd.to_numeric(df['OriginalBalance'], errors='coerce')df['DSCR'] = pd.to_numeric(df['DSCR'], errors='coerce')df.dropna(subset=['OriginalBalance', 'DSCR'], inplace=True)weighted_avg_dscr = (df['DSCR'] * df['OriginalBalance']).sum() / df['OriginalBalance'].sum()print(f"\nWeighted Average DSCR: {weighted_avg_dscr:.2f}x")
This workflow transforms unstructured public data into a verifiable metric. Without this programmatic approach, analysts are reliant on third-party data providers whose methodologies may not be transparent.
Implications for Modeling and Risk Monitoring
A verifiable data lineage fundamentally improves quantitative modeling, risk monitoring, and even Large Language Model (LLM) reasoning. When models are built on structured data linked directly to source filings, their outputs become explainable and defensible. For example, a credit risk model can pinpoint a spike in delinquency risk to specific loans whose performance degradation is documented in the latest 10-D servicer report.
This "model-in-context" approach moves beyond black-box analytics. It allows systems to answer questions with verifiable citations, such as "What is the current special servicing rate for the CMBS market vintage for 2024, and which specific loans in the BANK 2024-BNK48 transaction are contributing to that trend?" This level of granularity, grounded in source data, is essential for robust surveillance and is a core theme of the CMD+RVL framework for building explainable data pipelines. Full CMBS loan performance trends can be tracked with greater precision when tied to this methodology.
How Dealcharts Accelerates CMBS Analysis
Building and maintaining the data pipelines required to ingest, parse, and link CMBS data from public filings is a significant engineering challenge. The process is fraught with inconsistent formats, missing data, and the need for constant maintenance as filing standards evolve. Dealcharts connects these disparate datasets—filings, deals, shelves, tranches, and counterparties—so analysts can publish and share verified charts without rebuilding data pipelines. It provides a structured, queryable layer over the raw public data, allowing users to focus on generating insights rather than on data plumbing.
Conclusion
Understanding CMBS loans in a professional context requires moving beyond definitions to master the underlying data workflows. By establishing a clear data lineage from source filings to analytical output, analysts and quants can build more accurate models, conduct defensible risk surveillance, and create reproducible research. This commitment to data context and explainability, as championed by the CMD+RVL framework, is the foundation of modern, verifiable finance analytics. You can explore the structured data yourself at https://dealcharts.org.