LLM-Optimized Facts Endpoints
A Developer's Guide to LLM-Optimized Facts Endpoints for Finance
Large Language Models (LLMs) struggle to reason over structured finance data, which is often buried in disconnected EDGAR filings like 10-Ds, 10-Ks, and 424B5 prospectuses. The traditional workflow of manual parsing and data linking is slow, error-prone, and unscalable. While standard data APIs were an improvement, they weren't designed for AI; they serve raw, unstructured data that lacks the explicit context LLMs need to generate verifiable, accurate insights.
This guide explains why building proper LLM-optimized facts endpoints for finance is a critical shift toward verifiable, context-aware analytics. Instead of delivering entire documents, these endpoints provide atomic, machine-readable facts with provenance baked in, forming the foundation for reliable AI in capital markets. Platforms like Dealcharts help visualize and cite this kind of structured, interconnected data.
The Market Context: Why Traditional Data Access Fails in Structured Finance
The global structured finance market is projected to expand significantly, making efficient and accurate data analysis more critical than ever. Traditional data access methods, however, create severe bottlenecks for modern AI-driven workflows. An LLM cannot reliably interpret a PDF table without a schema; it might misread columns or misunderstand crucial footnotes. Standard APIs often return isolated data points, failing to connect a CMBS deal to its issuer's CIK, its servicers, or other deals in the same vintage.
Most importantly, when an LLM ingests raw text, its output is a black box. There is no way to trace a number in its response back to the specific source filing, page, and table. LLM-optimized endpoints solve these problems by providing a direct, programmatic path to interconnected data, linking deals, tranches, and counterparties into a coherent knowledge graph. This approach turns static documents into dynamic, verifiable facts, enabling reliable AI-powered tools for everything from monitoring 2024 CMBS vintages to automating risk surveillance.
The Technical Angle: Designing a Data Model with Provenance First
An LLM-optimized facts endpoint is only as reliable as its underlying data model. To build for trust and traceability, data lineage cannot be an afterthought—it must be the central organizing principle. This requires wrangling disparate sources like deal prospectuses and quarterly remittance reports into a coherent, machine-readable graph anchored by stable, universal identifiers.
Key identifiers like CUSIPs (for securities), CIKs (for SEC registrants), and LEIs (for legal entities) become the primary keys. Every fact, from a delinquency rate to a servicer fee, must be connected back to one or more of these keys. For instance, an issuer's entire history, like that of J.P. Morgan, can be traced by following its CIK. Financial data is also dynamic; deal terms are amended and reports are restated. The model must version all data snapshots with timestamps to enable point-in-time analysis.
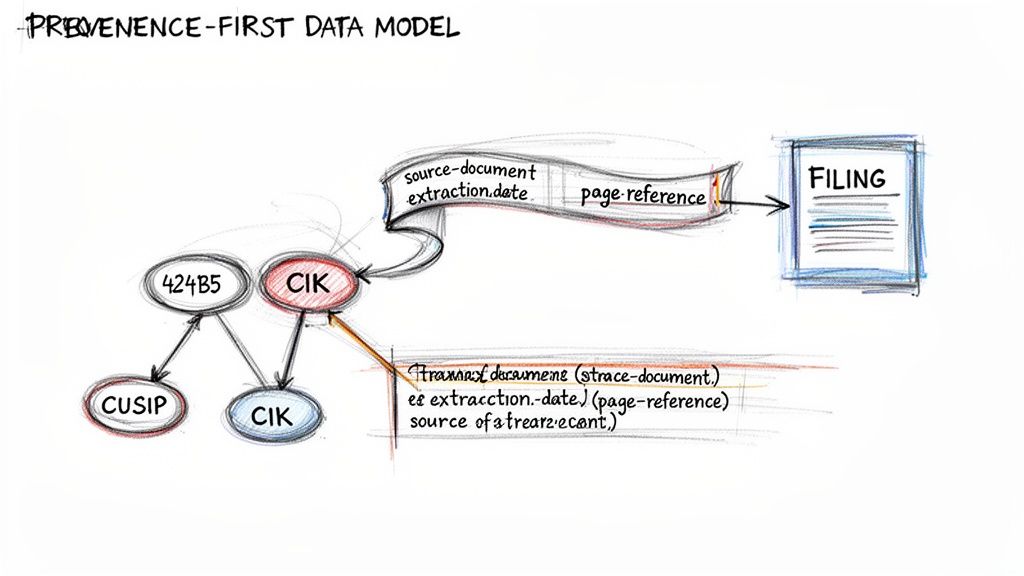
Most critically, provenance must be embedded directly into the schema for every data point. A number without a source is just noise.
A core principle for AI in finance is that an answer without a source is an opinion. A verifiable fact must be traceable to its origin document, page, and extraction context.
A weak model might store
. A provenance-first model provides the full story, turning a simple number into a verifiable fact that an LLM can cite with confidence.{ "credit_enhancement": 5.25 }
{"fact_id": "ce-jpmbb-2022-c16-a3","cusip": "46654XAN9","metric": "credit_enhancement_percentage","value": 5.25,"value_type": "float","as_of_date": "2022-09-15","provenance": {"source_document_id": "0001213900-22-056345","source_document_type": "424B5 Prospectus","page_reference": 47,"table_reference": "Summary of Terms","extracted_on": "2024-10-26T10:00:00Z","extraction_method": "structured_parser_v1.2"}}
This level of detail is non-negotiable for building trustworthy financial applications.
Example Workflow: Building a Context-Aware API Layer
With a provenance-first data model in place, the next step is building an API that mirrors how a financial analyst thinks. The API must handle complex, multi-layered questions, such as: "Find all CMBS deals issued in the last two years where the top three tenants are in the retail sector and have lease expirations before Q4 2025."
An LLM-optimized endpoint achieves this by supporting robust server-side filtering on nested properties (
). This lets an application request exactly what it needs, minimizing data payloads. A critical design principle is to reduce round trips by pre-fetching and embedding related context. When an app requests a deal by its CUSIP, the API should also return linked entities like the issuer and servicer, complete with their own stable identifiers. This pre-fetched context enables an LLM to answer follow-up questions without making additional expensive API calls.?deal_type=CMBS&issuance_year__gte=2023&top_tenants.sector=Retail
Here is a Python snippet demonstrating how to query a hypothetical
for specific, verifiable facts.dealcharts-api
import requestsimport json# Define the API endpoint and query parametersAPI_BASE_URL = "https://api.dealcharts.org/v1/deals"params = {"deal_type": "CMBS","collateral_type": "Office","issuance_date__gte": "2023-01-01","loan_to_value_ratio__lte": 65.0,"sort_by": "-principal_balance","limit": 5}# Execute the requestresponse = requests.get(API_BASE_URL, params=params)if response.status_code == 200:deals = response.json().get('data', [])for deal in deals:print(f"Deal Name: {deal['deal_name']} (CUSIP: {deal['cusip']})")print(f" LTV: {deal['attributes']['loan_to_value_ratio']}%")# The issuer context is pre-fetched and embedded in the responseissuer_name = deal['relationships']['issuer']['data']['name']issuer_cik = deal['relationships']['issuer']['data']['cik']print(f" Issuer: {issuer_name} (CIK: {issuer_cik})")print("-" * 20)else:print(f"Error: Received status code {response.status_code}")
This script queries for the top five office CMBS deals since 2023 with an LTV ratio of 65% or less. The response is a structured JSON object containing both deal attributes and linked issuer information, providing the context-rich data needed for reliable LLM reasoning.
Implications for AI: Powering Explainable Pipelines
Structuring data in this manner profoundly improves modeling, risk monitoring, and LLM reasoning. When an LLM operates on a foundation of verifiable facts, it transitions from a generative tool prone to hallucination into a reliable reasoning engine. This is the essence of building a "model-in-context," where the AI's conclusions are directly tied to an auditable data lineage.
This approach powers explainable pipelines. An analyst can challenge any AI-generated insight—for example, a sudden spike in reported delinquencies for the MSC 2021-L5 CMBS deal—and trace the claim back to the source remittance report, page, and table. This level of transparency is essential for building trust in AI systems for financial surveillance and due diligence. It transforms the AI from a black box into a transparent "context engine," a core theme of the CMD+RVL framework.
How Dealcharts Helps
Dealcharts connects these disparate datasets—filings, deals, shelves, tranches, and counterparties—so analysts can publish and share verified charts without rebuilding complex data pipelines. Our platform provides the foundational, provenance-first context graph needed to build reliable, AI-powered financial tools. The API is designed to deliver the structured, interconnected facts required to ground LLMs in verifiable reality, enabling the development of trustworthy and explainable analytics. Explore our open context graph at https://dealcharts.org.
Conclusion
LLM-optimized facts endpoints represent a fundamental shift in how financial data is prepared and consumed by AI. By prioritizing data lineage and embedding verifiable context directly into the API, developers can build systems that are not only powerful but also trustworthy and explainable. This programmatic, provenance-first approach is the only scalable path forward for building the next generation of reliable financial analytics, aligning with the CMD+RVL vision for reproducible, auditable insights.
Article created using Outrank