Tenant Improvements Guide
Tenant Improvements: Programmatic Analysis for CMBS and CRE
In commercial real estate (CRE), a tenant improvement (TI) is the capital a landlord invests to customize a space for a new tenant. For structured-finance analysts and data engineers, understanding TIs is crucial. It's not just about construction costs; it's a key financial lever in lease negotiations that directly impacts a property's net operating income (NOI), valuation, and the risk profile of associated commercial mortgage-backed securities (CMBS). Analyzing TI obligations requires tracing data from unstructured lease agreements and SEC filings into structured models for risk surveillance and programmatic analysis. Visualizing this data lineage is critical for accurate underwriting, a process easily managed in platforms like Dealcharts.
Market Context: Why Tenant Improvements Matter in CMBS
Tenant improvement allowances (TIAs)—the funds provided by a landlord for the build-out—are a standard component of modern lease economics, particularly in competitive office and retail markets. The size of the TIA is a direct reflection of market conditions, tenant creditworthiness, and lease duration. For CMBS analysts, future TI obligations represent a significant component of rollover risk. When major leases expire, the property owner must often fund substantial new TIs to retain tenants or attract new ones. This future capital outlay is a direct drain on a property's cash flow and must be factored into loan underwriting.
Current market trends, especially in a post-pandemic environment with fluctuating office occupancy rates, have intensified the focus on TIs. Landlords are offering more generous TIA packages to secure long-term leases with high-quality tenants. A 2022 CBRE report noted that over 70% of new U.S. office leases included a TIA, with allowances in major cities frequently reaching $75 to $100 per square foot. This trend increases the forward-looking capital burden on properties, a risk that must be quantified in CMBS deal analysis. The technical challenge for analysts is systematically extracting these TI commitments from disparate, unstructured documents to model their impact on future Net Cash Flow (NCF) and Debt Service Coverage Ratios (DSCR).
The Data Lineage of Tenant Improvement Allowances
For quants and data engineers, the core problem is data lineage: sourcing, parsing, and linking TI data. TI figures are buried within unstructured text in documents like 10-K filings, 424B5 prospectuses, and monthly CMBS servicer reports. These documents lack a standardized format, making programmatic extraction a significant challenge. One report might label a reserve "TI Escrow," while another calls it "Future Leasing Costs," breaking naive parsing scripts.
To perform analysis at scale, a developer must build a pipeline that can:
- Source Documents: Programmatically fetch relevant filings from sources like the SEC's EDGAR database for a given CMBS deal or property portfolio.
- Parse Text: Use regular expressions or NLP models to identify and extract key terms like "tenant improvement allowance," "leasing commissions," and associated dollar amounts or per-square-foot values.
- Link Entities: Connect the extracted data point to its corresponding property, loan, and CMBS transaction. A $500,000 TI reserve is useless without knowing which tenant lease in which building it applies to.
This process transforms raw text into a structured, queryable knowledge graph. The Dealcharts platform automates this pipeline, linking documents like the prospectus for the COMM 2012-CCRE1 transaction to the underlying loan and property data, enabling analysts to query TI reserves across an entire issuance shelf, such as the COMM shelf from JPMorgan Chase Commercial Mortgage Securities Corp..
Example: A Python Workflow for Extracting TI Data
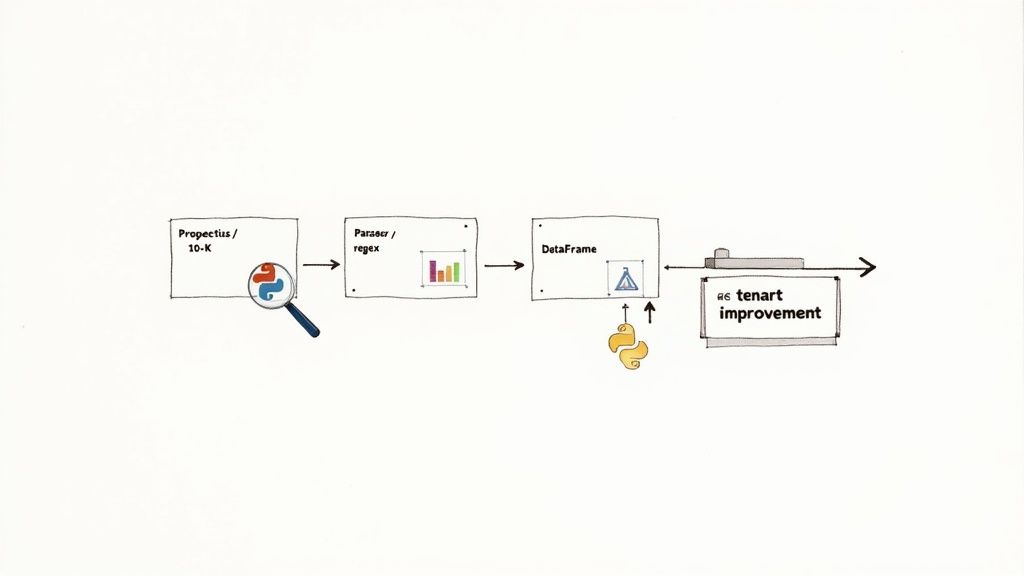
To demonstrate the data lineage concept (source → transform → insight), here is a simple Python snippet that parses a block of text from a hypothetical CMBS prospectus to extract structured TI data. This workflow is reproducible and highlights the transformation of unstructured text into an actionable dataset.
First, we define our source text and import the necessary libraries. We'll use
for regular expression-based parsing and pandas for structuring the output.re
# Import libraries for parsing and data structuringimport reimport pandas as pd# SOURCE: Sample text from a CMBS prospectusprospectus_text = """The largest tenant, a law firm occupying 25,000 sq. ft., has a lease expiring in 24 months.An upfront reserve of $625,000 has been established for future Tenant Improvements and LeasingCommissions (TILCs) related to this space. This reserve is based on a market rate of $25.00/sq. ft.to attract a new, high-quality tenant. The reserve will be held by the servicer."""
Next, we apply the transformation logic. We define regex patterns to find the total reserve amount, the per-square-foot (PSF) rate, and the total square footage.
# TRANSFORM: Define regex patterns and extract datareserve_pattern = re.compile(r'\$(\d{1,3}(,\d{3})*)')psf_pattern = re.compile(r'\$(\d+\.\d{2})/sq\.\sft\.')sqft_pattern = re.compile(r'(\d{1,3}(,\d{3})*)\s*sq\.\sft\.')# Search text using defined patternsreserve_match = reserve_pattern.search(prospectus_text)psf_match = psf_pattern.search(prospectus_text)sqft_match = sqft_pattern.search(prospectus_text)
Finally, we structure the extracted data into a pandas DataFrame, creating the final insight.
# INSIGHT: Structure the extracted data for analysisdata = {'Metric': ['Total TI Reserve', 'TI Allowance PSF', 'Total Square Feet'],'Value': [int(reserve_match.group(1).replace(',', '')) if reserve_match else None,float(psf_match.group(1)) if psf_match else None,int(sqft_match.group(1).replace(',', '')) if sqft_match else None]}ti_data_df = pd.DataFrame(data)print(ti_data_df)
This code traces a clear path from a raw text block to a structured table, ready for use in a larger financial model or risk dashboard.
Implications for Modeling and Risk Monitoring
Structuring TI data programmatically provides critical context that improves financial models and risk monitoring systems. With a verifiable data pipeline, analysts can:
- Improve Rollover Risk Models: Instead of using generic market-wide assumptions for TIs, models can incorporate deal-specific reserve amounts extracted directly from legal documents, leading to more accurate NCF projections.
- Enhance Surveillance: Automated monitoring can flag properties within a CMBS trust that have significant lease expirations approaching, allowing analysts to proactively assess the adequacy of existing TI reserves.
- Enable Context-Aware LLMs: A structured knowledge graph of TI data can be used to fine-tune Large Language Models (LLMs). This creates a "model-in-context" where an LLM can answer complex queries like, "Which loans in this portfolio have TI reserves below the submarket average?" with verifiable, sourced answers. This approach aligns with the CMD+RVL philosophy of building explainable pipelines that connect raw data to high-level insights.
How Dealcharts Helps
Dealcharts connects these disparate datasets—filings, deals, shelves, tranches, and counterparties—so analysts can publish and share verified charts without rebuilding data pipelines. The platform solves the data extraction and linkage problem for TI analysis by providing pre-parsed, structured data from CMBS and other ABS filings. Instead of wrestling with PDFs and regex, you can query TI reserves across an entire market segment, such as the CMBS vintage from 2024, to benchmark risk and identify outliers, turning a complex data engineering task into a simple analytical query.
Conclusion
Understanding what is tenant improvement is foundational, but the real value for financial professionals lies in programmatically accessing and analyzing TI data. By establishing a clear data lineage from unstructured documents to structured insights, analysts and quants can build more accurate risk models, enhance surveillance, and create more explainable financial analytics. This approach, central to the CMD+RVL framework, transforms opaque lease terms into transparent, verifiable inputs for data-driven decision-making.
Article created using Outrank